OpenAI开源模型Whisper实现音频转文字
一、Whisper安装
安装Whisper包
shellpip install openai-whisper测试Whisper是否安装成功,cmd输入下面命令
shellwhisper
安装ffmpeg,我本机已经有了,所以此步骤跳过,具体安装教程可见: windows安装ffmpeg的教程
二、whisper的使用
使用命令行(首次执行会下载模型,所以比较慢)
shellwhisper xxx.mp3 --model medium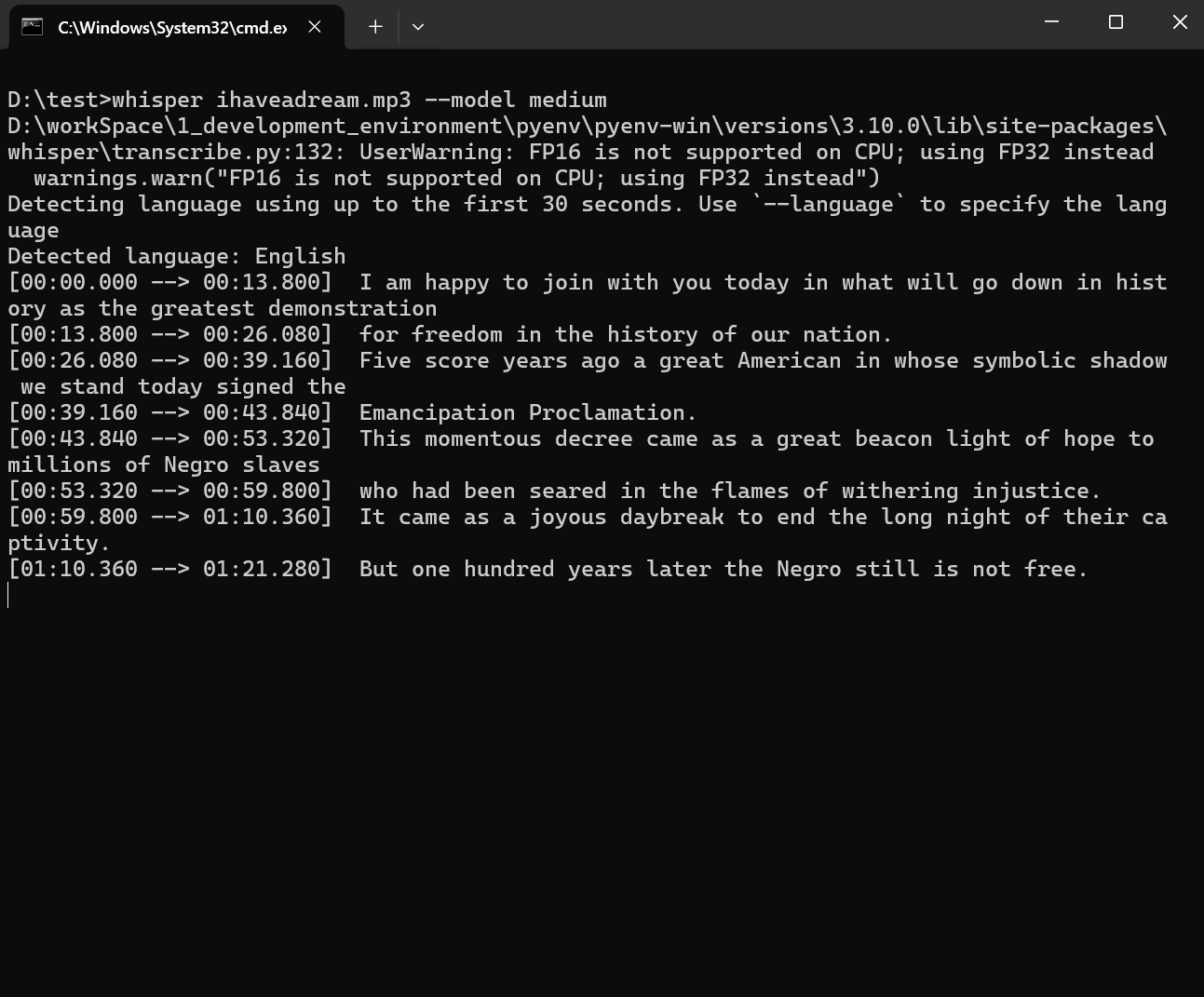
上图所示,whisper会先检测语言,当然也可以根据参数指定语言,whisper参数详解
shellwhisper --help
python代码
基本使用
pythonimport whisper model = whisper.load_model("medium") result = model.transcribe("baiyanglizan.mp3", fp16=False)
print(result["text"])
 - 指定语言为中文或者模型自动识别语言为中文时,识别的结果为繁体中文的解决方式:使用opencc库实现转换 ```shell # 安装opencc库 pip install openccpythonimport whisper import opencc model = whisper.load_model("medium") result = model.transcribe("baiyanglizan.mp3", fp16=False) cc = opencc.OpenCC("t2s") res = cc.convert(result['text']) print(res)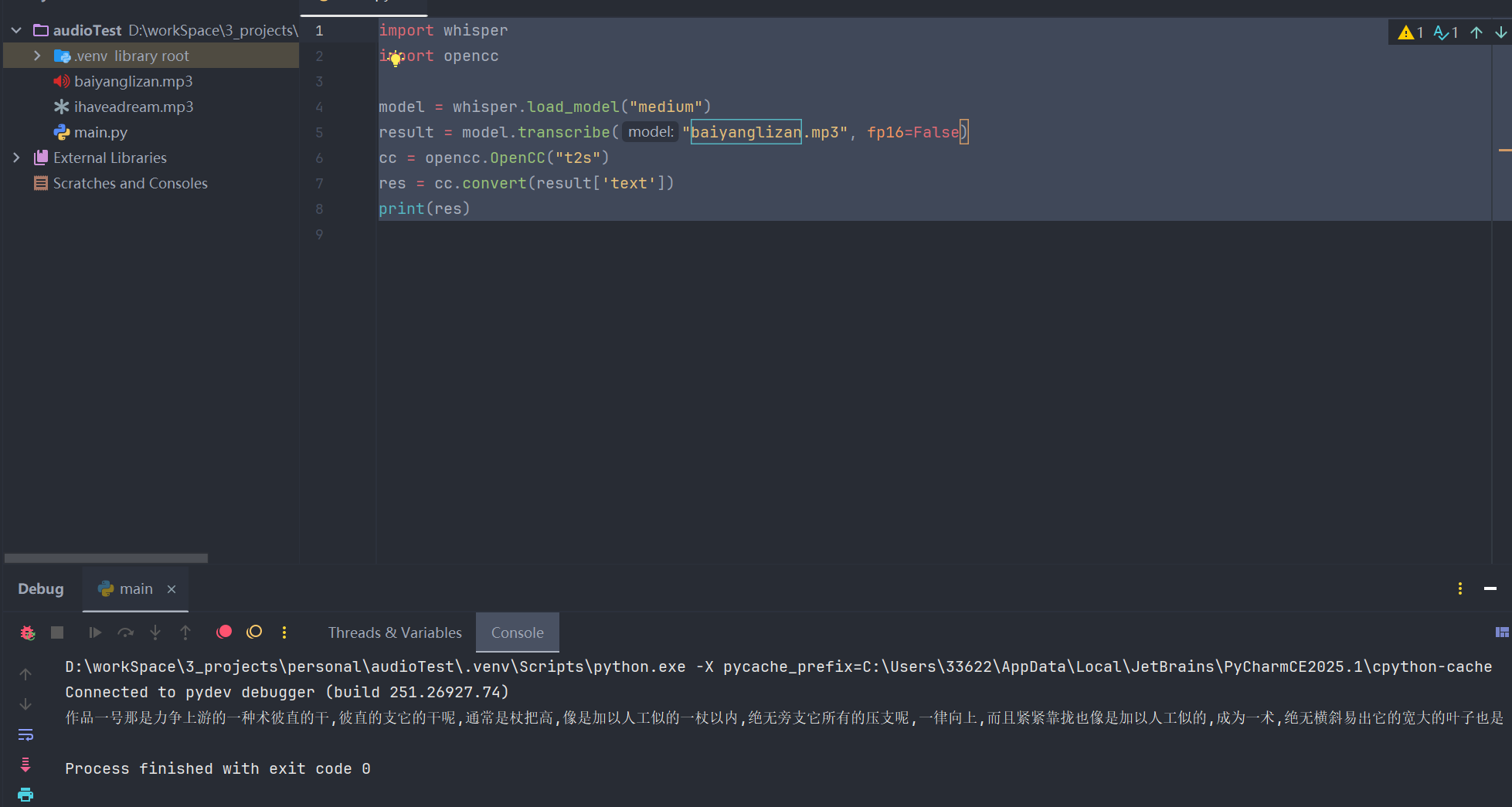
将识别的语音的语气停顿表示出来
pythonimport whisper import opencc model = whisper.load_model("medium") result = model.transcribe("baiyanglizan.mp3", fp16=False) cc = opencc.OpenCC("t2s") for i in result['segments']: res = cc.convert(i['text']) print(f"断句开始于{i['start']}秒,结束于{i['end']}秒,识别结果:{res}")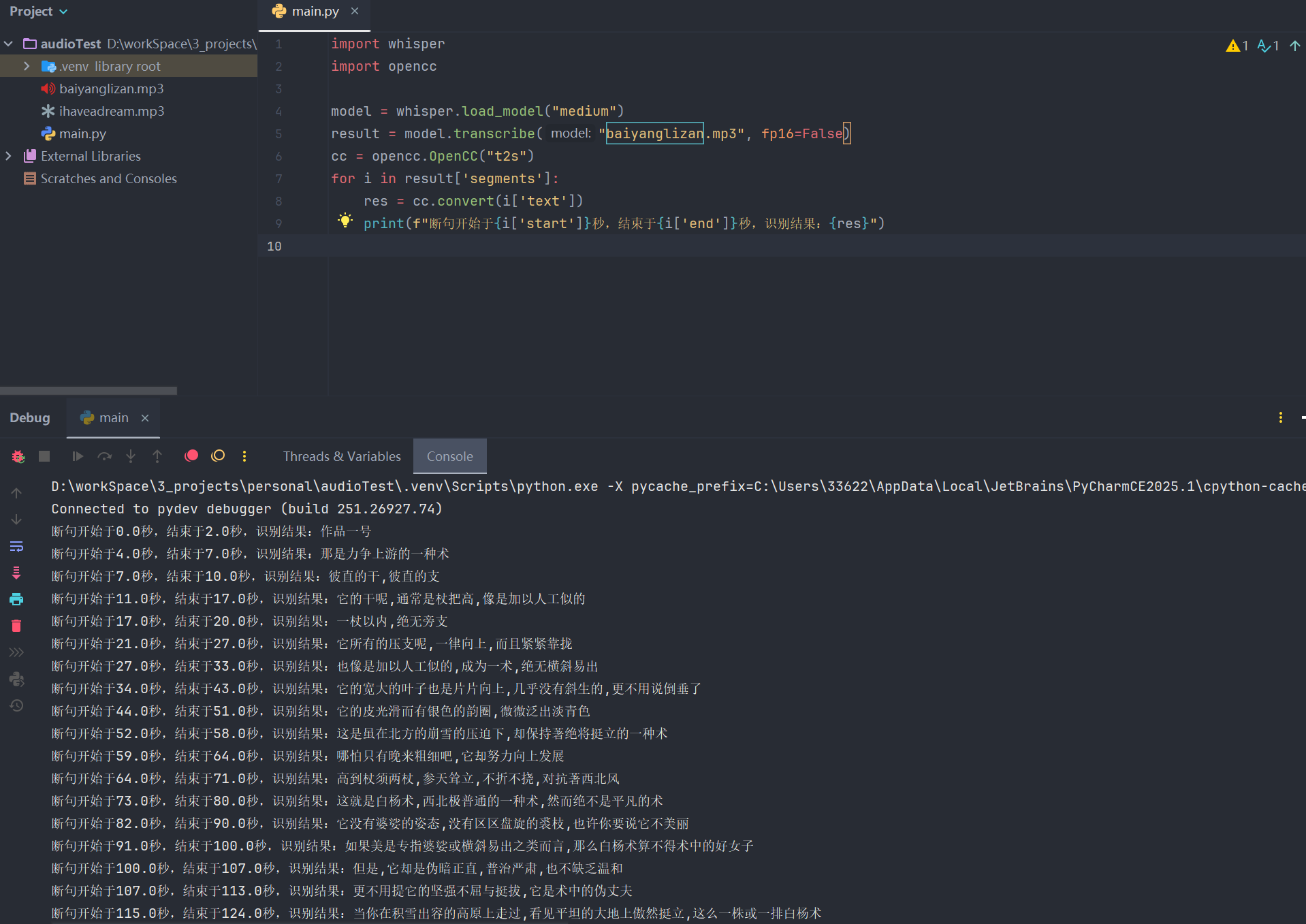
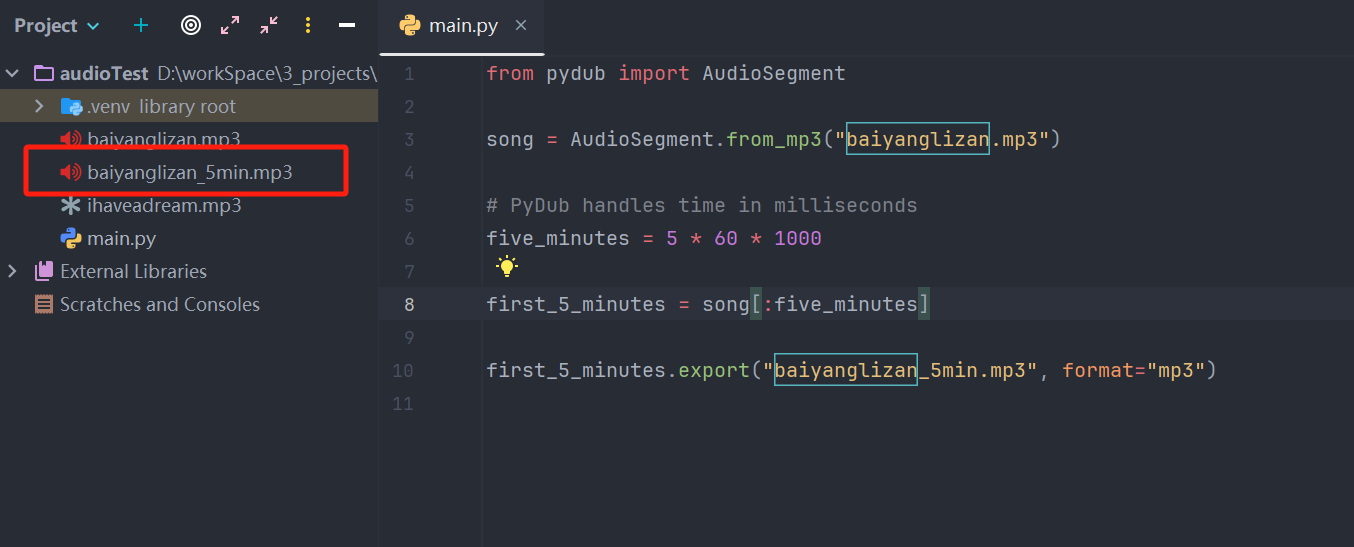
较长音频可以先使用pydub进行分块,分块后再进行转文字处理,下面代码是获取mp3的前五分钟的写法
shell# 安装pydub库 pip install pydubpythonfrom pydub import AudioSegment song = AudioSegment.from_mp3("baiyanglizan.mp3") # PyDub handles time in milliseconds five_minutes = 5 * 60 * 1000 first_5_minutes = song[:five_minutes] first_5_minutes.export("baiyanglizan_5min.mp3", format="mp3")