使用Python构建RAG系统
查看uv是否安装成功
shelluv --version如果未安装,执行下面命令安装
shell# 使用pip安装 pip install uv # 在windows上,使用官方提供的脚本安装 powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"创建项目文件夹,并进入,执行uv init命令初始化该python项目
shelluv init .
安装所需依赖
shelluv add sentence_transformers chromadb google-genai python-dotenv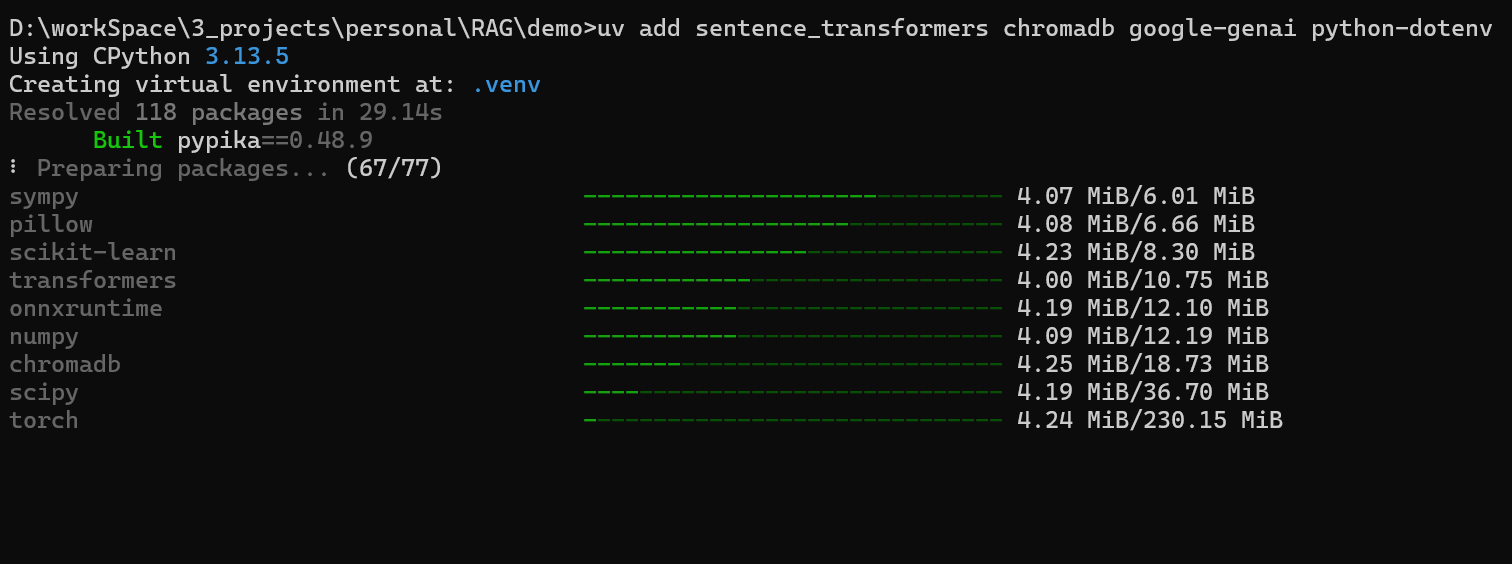
- sentence_transformer:加载 embedding 和 cross-encoder 模型
- chromadb:一个非常流行的向量数据库
- google-genai:Google的AI SDK,调用 gemini-2.5-flash 必备
- python-dotenv:将 gemini API Key 映射到环境变量中,以供Google AI读取
准备需要被检索的文档
使用uv启动Jupyter
shelluv run --with jupyter jupyter lab
代码实现
step1:分片(将文件内容进行分片)
pythonfrom typing import List # 将文件里的内容分片 def split_into_chunks(doc_file: str) -> List[str]: with open(doc_file, 'r', encoding='utf-8') as file: content = file.read() return [chunk for chunk in content.split("\n")] chunks = split_into_chunks("doc.md") for i, chunk in enumerate(chunks): print(f"[{i}] {chunk}\n")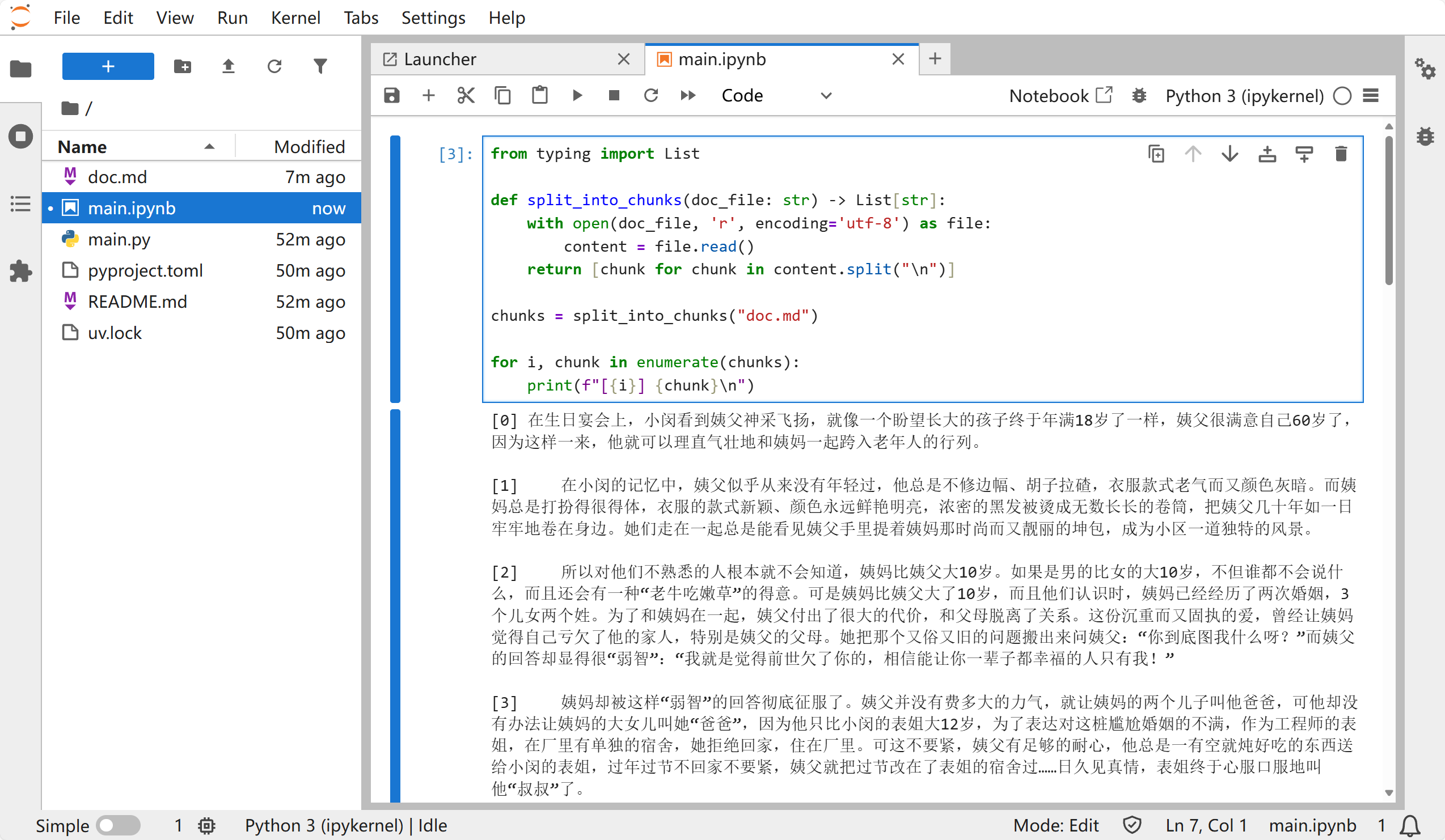
step2:索引(使用embedding模型计算片段的向量值) ,注意首次执行该代码会从huggingFace上下载模型,所以要确保能科学上网
pythonfrom sentence_transformers import SentenceTransformer embedding_model = SentenceTransformer("shibing624/text2vec-base-chinese") def embed_chunk(chunk: str) -> List[float]: embed_result = embedding_model.encode(chunk) return embed_result.tolist() test_result = embed_chunk("测试文本内容") # 打印向量维度 print(len(test_result)) # 打印向量值 print(test_result)
计算每个文本片段的向量值,可以看到24段文本都被计算成了向量值了
pythonembeddings = [embed_chunk(chunk) for chunk in chunks] print(len(embeddings))
将向量存储到向量数据库中,执行完毕后,在同级目录下生成向量数据库
pythonimport chromadb # 内存型向量数据库,数据不会写入磁盘,脚本运行结束之后自动清除数据 # chromadb_client = chromadb.EphemeralClient() # 内存型向量数据库,数据会写入磁盘 chromadb_client = chromadb.PersistentClient("./chroma.db") # collection 相当于关系型数据库中的表 chromadb_collection = chromadb_client.get_or_create_collection(name="default") # 定义保存文字片段和向量的方法 def save_embeddings(chunks: List[str], embeddings: List[List[float]]) -> None: # chromadb要求每个片段都需要一个编号 ids = [str(i) for i in range(len(chunks))] chromadb_collection.add ( documents=chunks, embeddings=embeddings, ids=ids ) save_embeddings(chunks, embeddings)
召回(找出与查询字符串向量值匹配度最高的5条分片内容)
pythondef retrive(query: str, top_n: int) -> List[str]: query_embedding = embed_chunk(query) results = chromadb_collection.query( query_embeddings=[query_embedding], n_results=top_n ) return results['documents'][0] query = "姐夫多少岁了" retrieved_chunks = retrive(query, 5) for i, chunk in enumerate(retrieved_chunks): print(f"[{i}] {chunk}\n")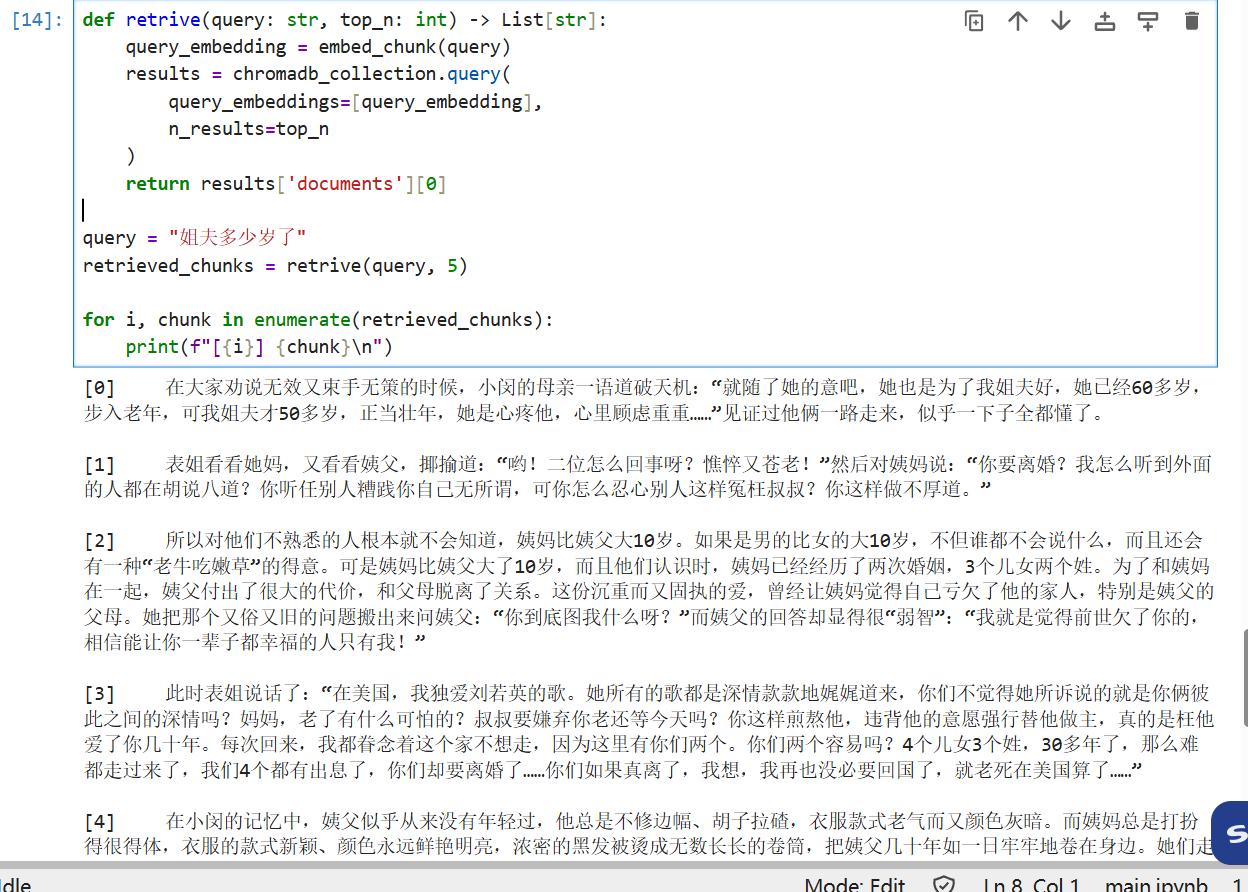
重排(使用cross-encoder模型对结果进行重排),注意首次执行该代码会从huggingFace上下载模型,所以要确保能科学上网
pythonfrom sentence_transformers import CrossEncoder def rerank(query: str, retrieved_chunks: List[str], top_k: int) -> List[str]: cross_encoder = CrossEncoder('cross-encoder/mmaro-mMiniLMv2-L12-H384-v1') pairs = [(query, retrieved_chunk) for chunk in retrieved_chunks] # 使用模型对每个召回的片段与查询语句进行打分 scores = cross_encoder.predict(pairs) # 将召回的片段按照匹配度进行排序 chunk_with_score_list = [(chunk, score) for chunk, score in zip(retrieved_chunk, scores)] chunk_with_score_list.sort(key=lambda pair: pair[1], reverse=True) # 取 top_k 个结果 return [chunk for chunk, _ in chunk_with_score_list][:top_k] rerank_chunks = rerank(query, retrieved_chunks, 3) for i, chunk in enumerate(rerank_chunks): print(f"[{i}] {chunk} \n")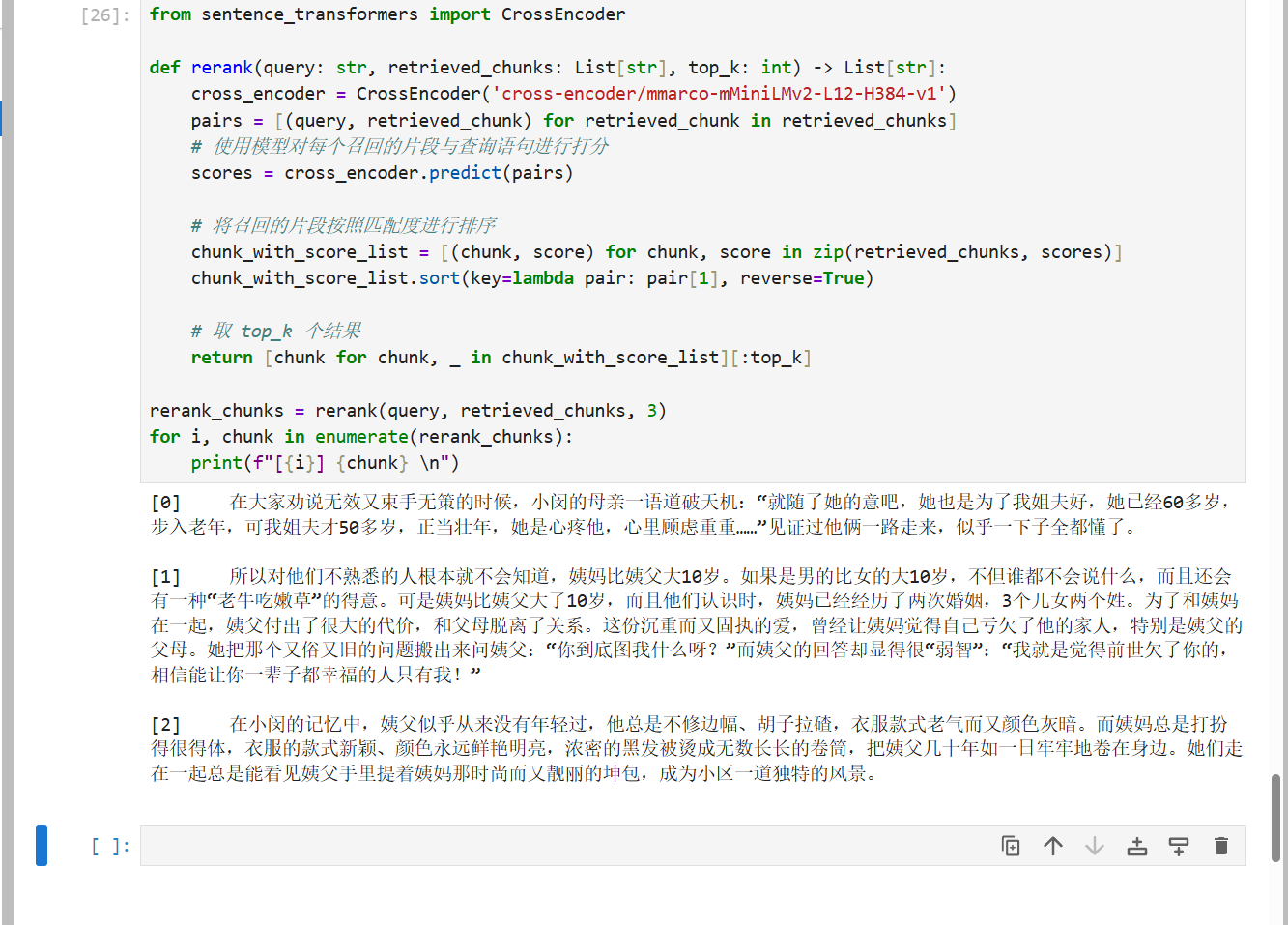
在项目根目录下生成一个.env的文件,文件内容如下
properties# 值为Google API Key GEMINI_API_KEY=XXX- 生成路径 Google API Key 的官网地址:Get API key | Google AI Studio
与Gemini 2.5 flash模型进行交互
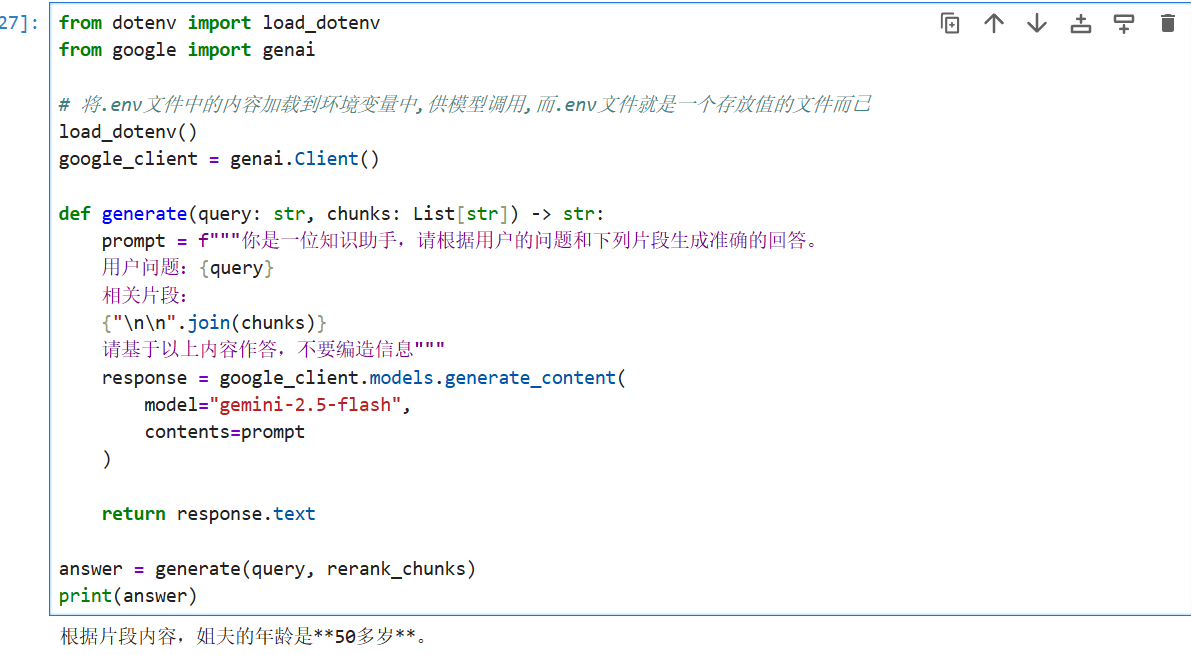
pythonfrom dotenv import load_dotenv from google import genai # 将.env文件中的内容加载到环境变量中,供模型调用,而.env文件就是一个存放值的文件而已 load_dotenv() google_client = genai.Client() def generate(query: str, chunks: List[str]) -> str: prompt = f"""你是一位知识助手,请根据用户的问题和下列片段生成准确的回答。 用户问题:{query} 相关片段: {"\n\n".join(chunks)} 请基于以上内容作答,不要编造信息""" response = google_client.models.generate_content( model="gemini-2.5-flash", contents=prompt ) return response.text answer = generate(query, rerank_chunks) print(answer)